LAPCAP Handbook
LAPCAP Handbook
The LAPCAP handbook gives practical steps and detail for how model development, quality assurance and signoff processes of LAPCAP and should be used by FPC team members to carry out the processes correctly.
For the background, theory and plan behind the approach you should read the LAPCAP Plan.
The below diagrams give an overview of the processes, with more detail included in later sections.
Coding Process Diagram 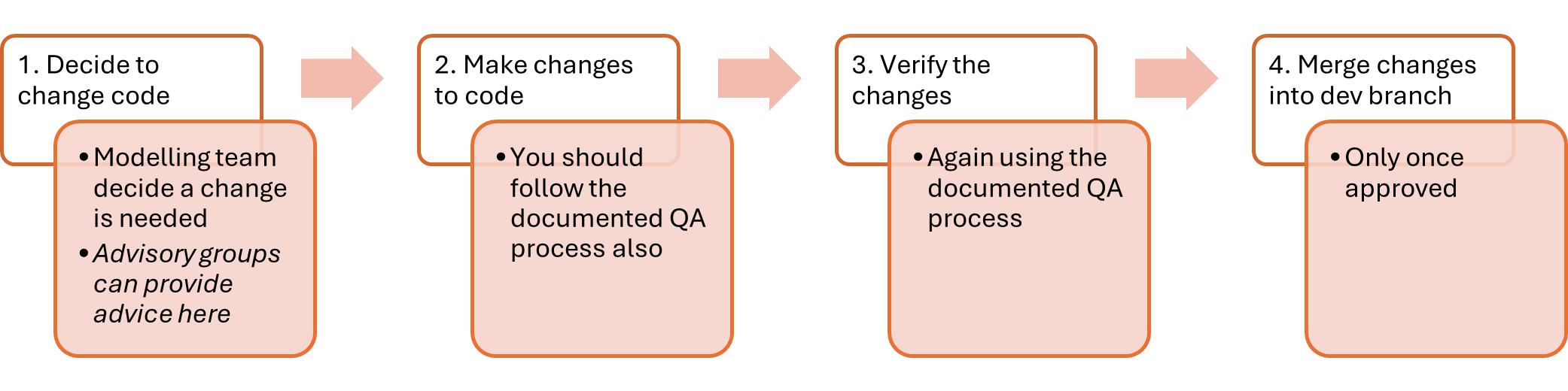
Signoff Process Diagram 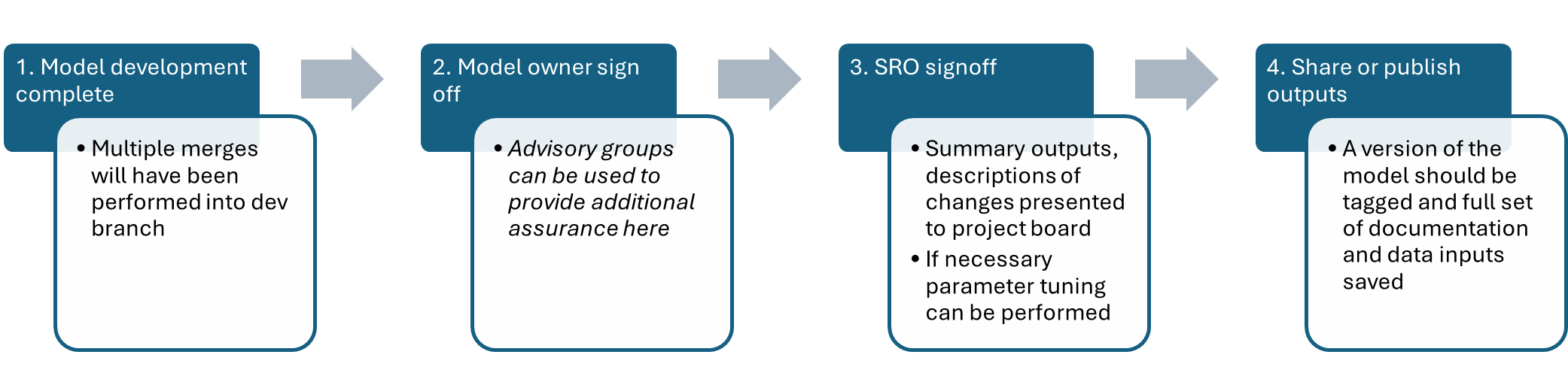
Coding Process Detail
1. Decide to change code
The modelling team, led by G7s, will identify the most important changes needed ahead of the next release of modelling outputs.
They may choose to make use of the Analytical Board, TWG or Sounding Board in determining this. They may also choose to seek signoff of their plans from the model owner or project board, or to simply make them aware, to ensure planned changes are expected.
An agile methodology using Jira is then used to plan out the delivery of these changes. Time for quality assurance should ALWAYS be built into each ticket in this planning, it should be understood that if there is not time for quality assurance then there is not time for the work.
2. Make changes to code
Team members will then take ownership of individual tasks, which should be clearly laid out in a single Jira ticket. Tasks should be as short and defined as possible with a clear endpoint. Story points will be used to make sure each team member has an appropriate workload in each sprint. With sprints lasting two weeks team members should be able to take on approximately 8 story points (estimated to be 8 days of work) in addition to their other responsibilities.
During completion of a ticket, changes will be made to the existing LAPCAP model through R Studio and Github. In order for multiple team members to work on the model at once we use Git, instructions for how to set this up can be found in the new starter section, whilst details on our use of branches can be found in the Model Versioning section.
In addition to changing the code, you may need to take additional steps, as follows:
a. If the changes involve adding, removing or changing an assumption then the modelling team member must update the relevant assumption log:
How to change an assumption
Identify an assumption.
We define assumptions as “choices analysts make to correct for low quality or absent data or information, that knowingly introduce inaccuracy into our outputs.”
Questions to help you determine whether a section of code is an assumption could be:
- Have you had to make a specific choice for how to model?
- Is your choice a simplification of reality?
- Theoretically were there other choices you could have made?
- Would changing your choice affect the final number?
- Is this information recorded elsewhere (e.g. in a data log or the technical document)?
Record your assumption in-code.
Paste the following code snippet below the relevant portion of code and edit to reflect the above.
# Assumption: Title of assumption # Quality: RED # Impact: AMBER # Detailed description # on one line or many.The title of the assumption should be short, clear and unique to this assumption.
The RAG rating is a red, amber or green rating summarising both the quality (e.g. how confident we are) and impact (e.g. how much model outputs are likely to be affected) of the assumption.
The detail description should give all information needed for someone to understand the assumption, including why an assumption is needed, why you have made the choice and more.
For more info on the package behind our assumptions log go to: Assumptions 1.1.0 Docs.
Record your assumption in the relevant assumptions log.
Each module has its own assumptions log which you can find via the LAPCAP library.
You will need to fill out the following fields:
ID - prefilled
Assumption title - same as reported in code
Detailed description - same as reported in code
Reporter - your name
Script(s) - which R script the assumption can be found in
Line(s) in code - which lines in the script are relevant
RAG - same as reported in code
RAG explanation - an explanation for why you gave the above RAG rating
Links to supporting evidence - any supporting evidence that you used in formulating this assumption, which should be stored in the corresponding ‘Supporting Evidence’ folder
b. If the changes involve updating a data import then the data pipeline must be refreshed and data logs updated:
How to modify the data pipeline
We have separated the code that processes our data inputs from the rest of the model,. this code is known as the data pipeline.The data pipeline is our way of version controlling input data for LAPCAP, meaning we can run previous versions of the model even if inputs have changed.
It works by reading the raw data inputs from AWS S3, processing them in R and then saving them back to AWS in a new version specific location. The model can then read from this location.
Therefore if you need to change, add or remove a data input or the way it is processed, you will need to edit the data pipeline. Guidance for how to do this can be found below.
Before you do anything else change the
model_versionparameter in any calls to the ‘data_pipeline’ function to a placeholder.This will prevent you from accidentally overwriting data being used by the “live” model, when working on the data pipeline itself (experimentation, testing, logic changes etc.) or updating/changing a data source,and ensures rolling-back to versions is easy in the future.
The pipeline will tell you if you are going to overwrite any data, but care should still be taken.
You should use a unique string for your model_version parameter e.g. “your_name_test”. This will be changed later when merging into dev.
Experiment and make the changes needed to the code.
Ensure you add the file_path and file_log logic to any new import functions (see the other import functions for details) – this will capture the new data sources in the file log.
If you are modifying the pipeline itself, you should note:
- There are dependencies between the sub-pipelines (e.g. waste flow using data from scheme data), so they will need to be run in order in any experimentation.
- If you are running pipeline functions outside of the pipeline itself, you will likely need to define the following variables:
s3_bucket <- "s3-ranch-043" root_folder <- "Module_B1/Inputs" file_log <- list()Once you have finished your experimentation/changes, update the model_version parameter to the next model version.
Follow the Model Versioning guidance) in both the argument to
data_pipeline()inupdate_data_pipeline.Rand the argument torun_LAPCAP_model()inmain.R.Run the pipeline to create a folder of data for that model version.
To run the data pipeline, run the
update_data_pipeline.Rscript. This will update to the latest version of the LAPCAP package, load all of the pipeline scripts, and run the pipeline (including saving the outputs to the aws bucket). This will create a new folder of processed data at “Module_B1/Inputs/Processed/” named after the model_version parameter.- If adding a data input, you should add it to the appropriate data log also.
Open a PR, follow QA processes and merge your changes into dev
Also delete any temporary folders you created in aws using your temporary model_version parameter.
Follow the Model Versioning guidance about tagging the new model version on dev
c. If model logic is changed then the technical document and unit tests must be updated accordingly.
How to update the technical document
Decide whether you need to change the technical document.
If your changes to the model you have created have changed the functionality of the model then you should update the relevent section of the technical document.
Furthermore, if a calculation is added or modified, then the example calculations section should also be updated.
No matter what, if a new script is added to the model (not the pipeline), the technical document should also be edited, even if there are no actual changes to model functionality. The related content section for the relevant module should be updated with the name of the new file created. This is because when the markdown is created it checks that all files have been covered in the technical document.
Edit the technical document working draft.
All updates to the technical document should first be written in the Microsoft Word based technical document working draft document stored in the model master folder. The sections of the technical document mirror the model modules, so it should be easy to find the sections you need to edit.
Some tips for writing high quality technical documents/example calculations include:
- Ensure you explain the model in terms that a non-technical person can understand
- Use as many diagrams as possible to aid understanding
- Use example calculations/equations frequently
- Don’t use any language like “I” or “we”
- If you are not sure how to write your section then read some other sections for guidance or ask someone to help.
- If you are updating the example calculations section there should be no surprises! Each variable you mention should have previously mentioned or you need to say where it has come from.
- All equations in example calculations should follow through.
Open a PR, follow QA processes and merge your changes into dev
As part of this, your reviewer should check the changes you have made to the technical document are adequate, so signpost what you have done in your PR.
Your role may end here, however in order to publish the technical document we have some additional steps.
The final technical document should be created using markdown, however, before any changes are made to the markdown, the following must happen.
- All updates to the working draft technical document should be checked. When the word document has been fully approved, only then should the markdown file be changed. (This is for your ease of use as it is much easier to edit a word document).
- All new files that have been covered in the updated technical document should be added to the related contents section in the markdown code.
- You should run the
generate_technical_documentfunction to check which files are not covered in the technical document. It may be fine for these files to not be covered, but if they include important functionality then update the technical document. - The technical document should be sent to relevant parties who want to check it. This should include the FPC team, members of adjoining teams, the G6 (Tristan), and any other people you think might want to add input.
- The HTML version of the example calculations section should be sent to the contents team to check if there are any significant changes. This is subject to it still being included in the LA guidance and published.
How to write a unit test
Unit tests are automated checks that verify individual functions or modules behave as expected. They act as a safety net when changing or adding features, ensuring existing functionality remains unchanged.
Unit tests should be used during development and whenever you run the
model. You can find all unit tests in the LAPCAP model in the
~/module_b/LAPCAP/tests folder. You should be able to click
on any one of them and run them as any normal function
(Ctrl+Shift+Enter). After which the test results will appear in the
“Console” pane. You will see messages like “Test passed” or error
messages if something goes wrong.
If you wish to run them all at the same time you can use: “testthat::test_dir(”~/module_b/LAPCAP/tests”)” which will execute all the files in that location.
Identify whether a test is needed, and what sort.
Unit tests should be used to test important model functionality, this may mean an individual function, or many. They should be included anywhere a failing function will impact model outputs.
Unit tests generally fall into three categories.
- Normal operation tests, verify the core functionality of the code using typical inputs. Most of our tests should be like this.
- Error fixing tests, confirm that known problematic inputs (e.g., NAs, zeros, negatives, mismatched names) are correctly handled or “fixed.”
- Error catching tests, ensure that inappropriate inputs trigger proper error messages and stop execution as intended.
Identify what it is about the model you want to ensure is protected and select a type of test that can do this.
Get your test input data.
Most unit tests function by comparing expected and actual results of a function on a fixed set of input data.
So we need fixed inputs in order to test our functions:
- Start by obtaining some real or dummy input data (or a subset of it) for the section of code you are testing.
- Apply the dput function to your downsized datasets. This will output (in the console) code that can be used to produce your dummy dataset as required.
If you are testing error fixing or catching you may wish to intentionally introduce some incorrect data here.
Get your output data.
Either manually or by using code you know to be correct, generate the outputs that should result from running the test input data through your function.
If you are testing error catching there may not be a correct output, an error message may be expected instead.
Write your test.
We use the testthat package, which provides functions like expect_equal, expect_identical, and expect_error that allow you to compare actual and expected outcomes.
A template is provided below, you should add detail to the description as well as changing object names:
#' @title Unit test 1 #' @description Tests the normal operation of function_name [ADD DETAIL] testthat::test_that("function name normal operation test", { #Create dummy data function_name_ut1_input_data_1 <- #Paste dput of first three or four rows and relevant columns of dataset function_name_ut1_input_data_2 <- #Same again function_name_ut1_output_data <- #Paste dput of expected outputs or write code to manually calculate these #Test testthat::expect_equal( function_name( function_name_ut1_input_data_1, function_name_ut1_input_data_2 ), function_name_ut1_output_data ) })It is important to name your test files clearly (e.g., test_inflate_costs.R, test_align_facility.R) so that it is immediately obvious which module or function each test is verifying.
Finally you should run your unit tests to ensure they pass, and also tweak your functions to check they fail when they should. This will also be reviewed as part of your pull request.
d. If the changes will affect model outputs, then validation checks must be carried out.
How to run validation checks
Validation checks ensure the model is performing as we expect. We currently have three validation processes in place, outlined below. These have been mostly automated so should be easy!
Change log
This allows us to check the percentage difference between the outputs from the last tagged version of LAPCAP and the output of whatever changes you have made.
This should be done via the spreadsheet named “[model_version] model output sensitivity testing.xlsx” on the Module B1 Sharepoint, within 00 Model Master folder > [model_version].
Follow the comprehensive instructions in the first sheet.
The spreadsheet automatically highlights any percentage changes above the acceptable threshold. If values become highlighted, make sure to check with a Grade 7 whether the need for the change justifies the change in outputs.
Critical Success Factors (CSF) markdown
We generate and inspect the Critical Success Factors (CSF) markdown to ensure the change hasn’t violated any of the success factors. These success factors are the principles that the model has to meet, as agreed by the four nations.
Use the function generate_validation_markdowns() in documents in the LAPCAP repo to generate the markdown, following the instructions in the function’s roxygen header
Inspect the output, ensuring that each CSF is still being met. If you have any concerns, raise them with a G7 or above.
Download a version of the output so you can link it in the pull request template later.
Internal Validation markdown
PROCESS TBD - STILL IN DEVELOPMENT
Locations for assumption log, data log or the technical document can be found in the LAPCAP library, and each includes further instructions for how to use it.
Once you have satisfied the requirements of your ticket, all of the above have been addressed and you are ready for someone to review your work, you should make a pull request via Github.
How to make a pull request
Once the modelling team member has completed their changes, they should make a pull request and request a review from another member of the team.
Here are the step-by-step instructions to submit a pull request:
Go to the relevant repo on Github and navigate to your branch
Use either the branches drop down or click on ‘x branches’ to go to the branches page and select your branch.

If your push was recent there may be a pop up allowing you to ‘compare and pull request’, if not then click ‘Contribute’ and ‘Open pull request’.
Make sure you are merging to the correct branch, this will usually be dev (for code in development) or sometimes main if it has been fully quality assured.

Fill out the pull request template (following carrying out validation checks, see below), including adding any additional QA checks to the list.
Replace this gif with one that describes how you felt about completing this ticket:

✔️ QA checklists
📝 Description of changes made:
🎟️ Link to Jira ticket:
🤔 Link to QA log (assumptions or data log), if changed:
💾 If appropriate, link to CSF markdown:
📈 If appropriate, link to output percentage change spreadsheet:
% change in EPR Total Net Cost Mean absolute change per LA Overall England Scotland Wales NI 🌜 Do-er QA checklist
Before submitting a pull request the principle analyst must have completed the below checks.
Some suggestions for additional checks are included in the template also:
Additional checks
The below is a list of QA checks that reviewers may want to perform in addition to the above. Note that this lists is not exhaustive and it is the responsibility of the principle analyst (do-er) and the QAer (checker) to ensure all items that need to be checked have been:
- Check that the calculations done are fit for purpose and are correct
- Check that uncertainty has been considered and appropriately accounted for (e.g. has sensitivity analysis been performed)
- Check that the data used is fit for purpose and the best option available to us
- Check that other appropriate documentation has been completed or updated to an appropriate standard e.g. the technical document
- Is the data being correctly pulled into the model?
- Is the data being properly cleaned and manipulated (either before the model or during the code)?
- Has the data been verified and validated? Has it been checked for potential errors? And has it been confirmed that the data appropriate to use in the first place? Is it the best possible option?
- Are there other results other than the outputs of the last model that the results need to be compared to?
- In cases where new data is added, or a change is heavily dependent upon a particular data source, does the model respond as expected to extreme values, negatives, zeroes, NAs etc? Is it possible to break the model with the data or generate impossible results?
These, or other checks, should be added to the checker’s checklist, as appropriate, in the PR to ensure they are completing all the checks required.
Click ‘Reviewer’ and select the person who has agreed to review your code.
Then you can click ‘Create pull request’.
- Once you have created the pull request you should move the ticket to ‘For Review’ on Jira.
3. Verify the changes
Once assigned a review the team member must complete the full checklist provided by the principle analyst. It is also the QAers must also review the list critically and ensure that it is both appropriate and sufficient. If the QAer feels otherwise they must raise this with in the first instance the principle analyst and then failing this the model owner.
You should use the checklist below, which is also included in the pull request template, to ensure you carry out all necessary checks:
🌛 Checker QA checklist
Before approving a pull request the reviewer must have completed the below checks: In addition to the above, the following is a checklist for the reviewer to use:
Also you should carry out any additional checks required, which have been added to the Checker Checklist by the doer.
Reviewers should trace the full logic of the code, both by reading through it and by running it and spot-checking intermediate data frames. They should inspect any relevant data imports both in R Studio and directly from their original source. They should examine model outputs before and after the changes to ensure they make sense. They should make sure they are able to replicate any processes or calculations in the code.
Reviewers should leave comments via GitHub, to ensure a record of verification and validation. GitHub has several features to help with this such as filtering changes by commit or file type, marking scripts as viewed, making direct code suggestions and bundling many comments into one review.
These reviews may go through one or more cycles of requesting changes, in order for the reviewer to be happy. GitHub has functionality to enable this.
The following explains the practical steps followed in when reviewing code:
How to do a code review
This Github code review tutorial shows you how to review a pull request, or you can follow the steps below.
Follow these step-by-step instructions to do a proper code review:
Navigate to the ‘pull request’ that has been assigned to you. Read the description provided and use the checklist to aid your review.
Switch to the ‘Files changed’ tab to see the changes made, here you can make comments and suggestions as you see fit by clicking the blue plus to the left of the line you want to comment on.

- Make sure to tick ‘Start a review’ rather than ‘Add single comment’.
- Github has lots of functionality to make this process easier, including being able to mark scripts as ‘Viewed’ and limiting changes to certain commits.
- You should also run the code in R Studio and check the relevant QA log has been updated.
When you are ready click ‘Finish your review’ add a summary comment and then click ‘Submit review’. You may choose to leave comments to be responded to, suggest changes to be made or simply approve the pull request straight away.
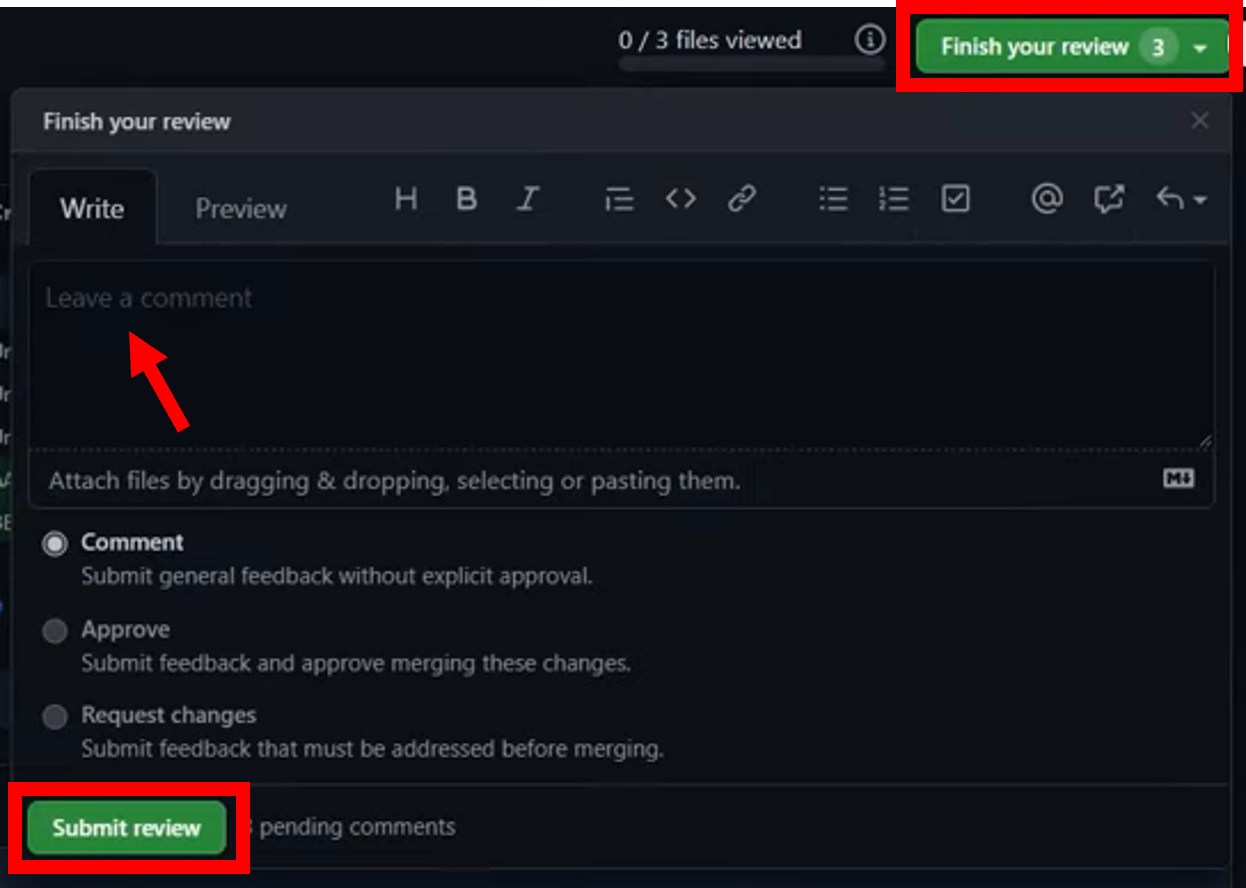
The QAer should then write a summary of the checks performed. In particular noting issues and any unusual checks that have had to be performed in the process of QAing.
4. Merge changes into dev branch
Once approved, changes should be merged into the dev branch. This may require resolving merge conflicts.
How to merge
Once your reviewer has inspected your code they may ask you some questions or suggest some changes. Once you have responded to these they will approve your pull request and you can merge your changes! This will look like:
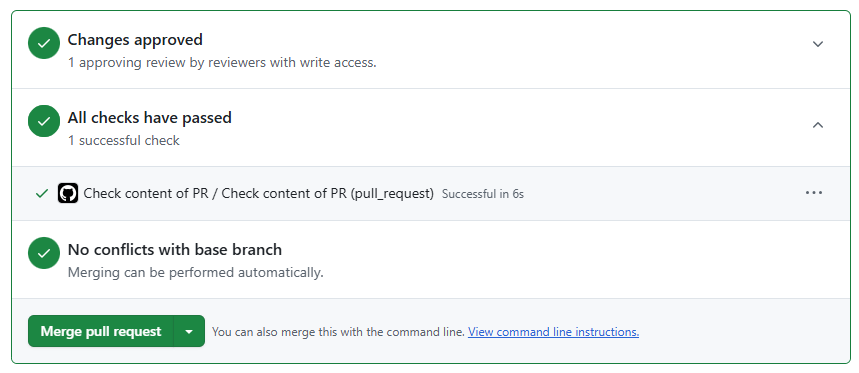
Note: if any of the QA checklist items have been left unchecked, GitHub will automatically block merging. It will look like:
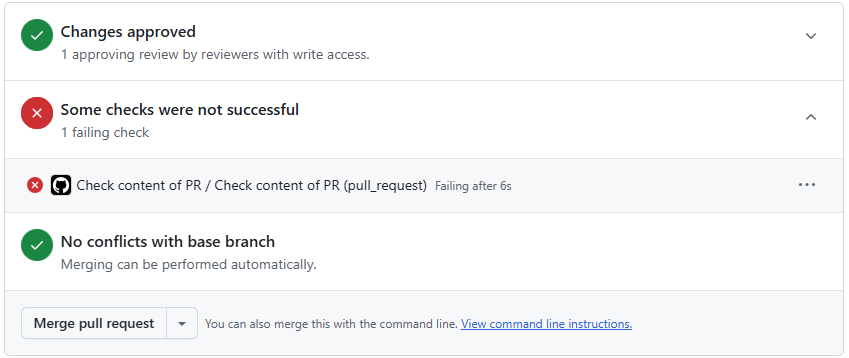
You will need to check there are no ‘merge conflicts’. This is where someone has changed the same files as you and so you need to agree with that person what are the correct changes and modify accordingly, Github will read ‘Able to merge’ indicating there are no conflicts.

If you are merging a new tagged version of the model…
You will need to make sure:
You have changed the model_version parameter in
run_LAPCAP_model(inmain.R) and the model_version parameter in the data_pipeline function inupdate_data_pipeline.R.Version numbers should follow this convention: in version Vx.y.z,
- The first number, x, should be updated when figures are published externally (including publishing letters, use in public base fees etc.)
- The second number, y, should be updated when figures are shared non-publically (e.g. with Simpler Recycling, MHCLG, DESNZ etc.)
- The third number, z, should be updated when there are changes to the data inputs or the data pipeline (to allow rolling back to the correct data in the future)
You have run the data pipeline with the new model_version parameter to create a folder on the aws bucket containing all the data for that version of the model (remembering to restart your R session and clean your environment before running the pipeline) - see here for full data pipeline guidance
Ensure that the data pipeline and model both run correctly with the new model_version parameter
After merging you can then tag the commit on dev with the new model version using GitHub’s tagging feature. If publishing externally and updating the first number in the model version, you should open a PR and merge dev into main, after signoff processes have been completed.
You should ensure that the rest of the team are aware of the version being tagged so they can rebase their branches if necessary.
Finally you can delete the old, now redundant branch you were working on!
Finally the QA analyst (or the appropriate G7) will review the pull requests on a weekly basis to ensure that they been done to a high standard.and record them in the verification log 03 LAPCAP Signoff Log.xlsm. This will allow us to effectively communicate the steps taken to ensure quality with stakeholders and inspire confidence.
Signoff Process Detail
1. Model development complete
Once all changes required for a publication or sharing of the model are complete, the team will undertake the following steps.
Multiple pull requests will have been merged into dev (e.g. the above coding process will have been repeated multiple times) and these will all receive signoff together.
There are some circumstances where the full signoff may not be required for instance, sharing the model internally, this is left to the judgment of the model owner.
2. Model owner signoff
The TEMPLATE model_owner_signoff_request.docx should be used to request a sign off from the model owner. It contains instructions for how to fill it out.
The model owner should sign off on the following documents, which should have been updated:
Documentation
Technical document
Assumptions logs & accompanying evidence
Data logs
Verification log compiled by quality assurance lead
Outputs
Change log
Critical success factors markdown - which can be updated following the steps under How to run validation checks
The validation markdown - STILL BEING REVISED BY CAT
The model owner does not necessarily have to review all of these themselves; they may utilise the advisory groups to offer assurance. For instance, in the past TWG have assured on assumptions logs.
The model owner’s signoff for that model version should be recorded in 03 LAPCAP Signoff Log.
3. SRO signoff
PackUK Executive Committee, or pEPR Project Board in their absence, acting on behalf of the model SROs, should signoff the model version for publication.
It is unlikely that members of project board will review any of the model or its documentation themselves, however copies should be shared so they have the option to, and can delegate to members of their organisation.
Instead, summaries of changes, visualisations of overall outputs and assurances from advisory groups may be presented. Exactly what is required may depend on the specific changes being signed off, so is left up to the judgment of the model owner.
The paper or presentation submitted to the SROs should be approved by Analytical Board in order to allow the SROs confidence in the analytical quality of the model before formal approval for use.
There may be an additional stage of parameter setting, at this point in the approvals process, especially for the first outputs for each new year of EPR.
The project board signoff for that model version should be recorded in 03 LAPCAP Signoff Log.